概述
昨晚在电话面试的时候,面试官问我Java多线程的实现方式,使用什么数据结构?说实话,我没有get到点,不过这也勾起了
我的疑问,Java的线程池到底是怎么实现的?
今天来就把jdk1.8的源码扯出来,准备看一下线程池这块的实现方式。线程池这块的核心类是ThreadPoolExecutor,也是本文分析
的主体。
可能网上的源码解析已经很多了,但是,我不自己看一下,还是觉得没理解,看了就得记一下。
早上被拉去开会了,中午刚好看了一会儿线程池源码,得,中午面试又问到这了,嘿嘿嘿。
组件介绍
ctl变量
ctl变量是ThreadPoolExecutor类的第一个变量,该变量是一个原子变量,其中存储了线程池的两个信息:
- workerCount,表示有效的线程数目
- runState, 表示当前线程池的运行状态,running,shutdown,stop或者其他。
代码如下:
1 | private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); |
下面用一幅图来帮助大家理解
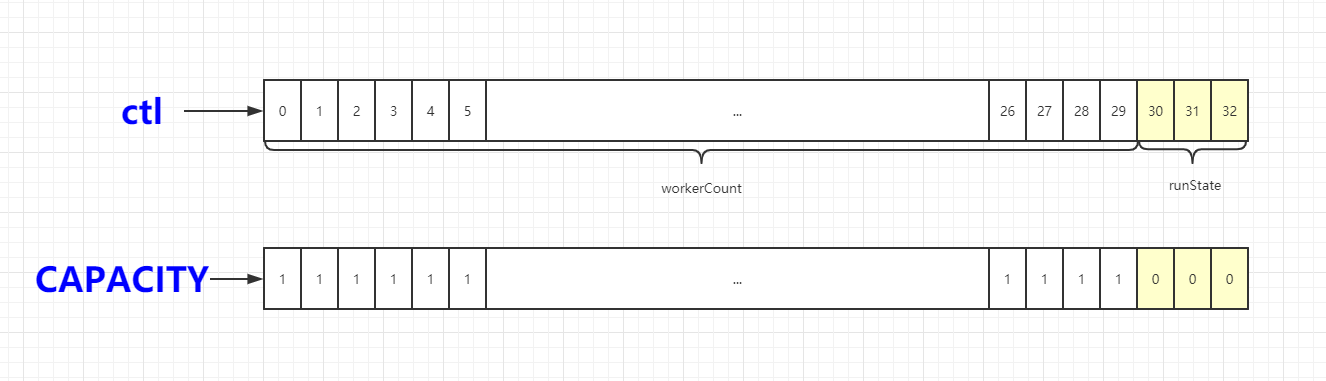
从上图中,结合代码,我们很容易理解CAPACITY的用途,通过&操作从ctl变量中解析出workerCount和runState变量。对于其他几个变量入RUNNING,SHUTDOWN,STOP,TIDYING和TERMINATED,也就不难理解了。需要注意的是,RUNNING的数值最小。
代码中接下来有若干个私有方法,都是与ctl变量解析和操作相关的,无非两类:
- workerCount的数目原子性增减
- runState的原子性修改
若干简单变量
- workQueue变量。这个变量理解起来很简单,任务队列
- mainLock变量。用来进行并发控制的,后续用到了很容易理解
- largestPoolSize变量。用来存储线程池数目的历史峰值,比较好理解
- completedTaskCount变量。存储线程池已经完成的任务总数
- threadFactory变量。用来创建县城的工厂类
- handler变量。线程池的拒绝策略
- keepAliveTime变量。指定worker允许空闲的最大时间
- allowCoreThreadTimeOut变量。是否允许核心线程被终止
- corePoolSize。核心线程数
- maximumPoolSize。最大线程数
其他。
Worker类
Worker类是线程池内部类,继承了AQS类并实现了Runnable接口。其内部变量如下:
- Runnable实例。
- Thread实例。该实例持有Worker本身。
- completedTasks
对于一个Worker实例,在实际运行中,是由其持有的Thread实例通过start()方法,运行Worker实例的run方法,最终调用了runWorker方法,在runWorker方法中,调用了Runnable实例的run方法。
暂时可以这样简单的理解,每一个worker都是一个线程。
runWorker方法及其他
runWorker
在上一节中,我们知道每一个worker实例都是一个工作的线程,那么我们想知道线程池怎么实现一直运行,怎么实现没有任务的时候将线程降低到核心线程数的?这些在runWorker方法中,我们都可以找到答案。
可以看到,runWorker方法内部有一个循环,这个循环如果结束,那么worker就执行结束了,线程就退出了,那么,线程池保留核心线程数量的原理肯定存在于while条件中的getTask()方法,这个方法,下一节会讲到。
我们先看一下while循环内部的逻辑吧。
- 首先,获取任务。该循环通过getTask方法获取Runnable实例,实际上是从workQueue中获取任务。
- beforeExecute和afterExecute钩子函数。这两个函数可以在扩展ThreadPoolExecutor的时候,进行扩展,默认情况先是不做什么事情的。
- 可以看到task.run()调用,是核心逻辑,也就是在这里,执行了我们提交给线程池的任务。
1 | final void runWorker(Worker w) { |
getTask
本节分析getTask方法的逻辑。可以看到,该方法内部是一个循环,其逻辑如下:
- 首先是判断当前线程池的状态,如果已经属于shutdown状态了,自然需要进行一些处理,然后返回null,结合上一节,我们知道,每一个执行到这里的worker线程,都将会结束,迎来其线程的死亡。
- 获取当前的worker数量,如果数量大于maximumPoolSize且任务队列是空,那么就对workerCount进行原子性减一,并返回null,结束当前worker线程。如果原子性减一失败,那么就进入下一次循环。这一点很好理解。
- 从workQueue总take任务,获取到的任务不是null,就返回任务。如果是null,就要考虑接下的事情了。此时timedOut被设置为true,表示我们在任务队列中没有得到任务,要考虑是否降低线程数目了。
- 可以看到timed 在当前workerCount大于核心线程数或者allowCoreThreadTimeOut设置为true时成立,从3中我们知道,timedOut在未能从workQueue中获取到数据。那么后续进入条件判断内部,返回null,导致worker线程结束
- 如果allowCoreThreadTimeOut设置为ture,那么空闲期线程池也可以不存在核心线程在运行
1 | private Runnable getTask() { |
小结
其实,到这里,我们已经理解了:
- 线程池如何从阻塞队列中获取数据
- 线程池如何维持一定数量的核心线程一直保持运行
接下来,我们看看execute方法。
execute方法
有了上面的基础,我们再来看看execute方法吧,其执行逻辑有四个分支
- 如果当前的workerCount小于corePoolSize,直接addWorker即可
- 如果workerCount已经大于corePoolSize,就向workQueue中添加任务
- 如果添加失败,那么调用addWorker方法,准备增加线程数
- 如果以上都失败,说明无法加入任务了,调用reject方法,拒绝任务提交
可以看到核心在于addWorker方法,下一节就来看看addWorker方法吧
1 | public void execute(Runnable command) { |
addWorker方法
addWorker方法除了任务参数,还有一个core布尔量,表示着是否是在增加核心线程,这肯定是有区别的。
可以看到在retry循环,主要目的:
- 如果线程池状态异常,那么直接返回false
- 如果线程池数量大于maximumPoolSize,或者core等于true时当前线程数大于corePoolSize,那么直接返回false
- 增加线程数统计,成功,循环结束,执行接下来的代码,否则,继续循环
接下来的代码,结合前面我们的代码分析,很好理解了:
- 新创建一个worker,入参为传入的任务
- 后去新建worker的线程实例
- 加mainLock锁,因为我们需要更新workers和largestPoolSize这样的共享变量
- 执行worker的线程实例的start方法,线程开始执行
其中还有一些流程控制的东西,很容易理解
1 | private boolean addWorker(Runnable firstTask, boolean core) { |
总结
这是我在今天阅读ThreadPoolExecutor源码时候的一些思路,当然,这是在总结之后的,开始的时候,也是无头苍蝇,乱撞。
希望这篇文章对想要知道ThreadPoolExecutor底层实现的朋友带来一点启发。
下面我需要对AQS也做一次总结,之前看过,不总结,忘了,好烦。